A website to manage orders for local food baskets.
Project built using Django, Bootstrap and JavaScript.
- Background and goal
- Features
- Dependencies
- Run using Docker
- Populate dummy database
- Configure SMTP
- Tests run
- API Reference
- UI Language
This project has been developed to meet a real need for a local association.
The aforementioned association centralizes orders for several local food producers.
Thus, food baskets are delivered regularly to users.
Before the deployment of this application, administrators got orders from users via SMS or email.
Baskets app aims to save them time by gathering user orders in one unique tool.
Payments are managed outside this application.
- Sign In page:
- User account creation entering personal information and setting a password.
- Passwords are validated to prevent weak passwords.
- A verification email is sent to user with a link to a page allowing them to confirm their email address.
- Sign Up page:
- Users with verified email can log in using their email and password.
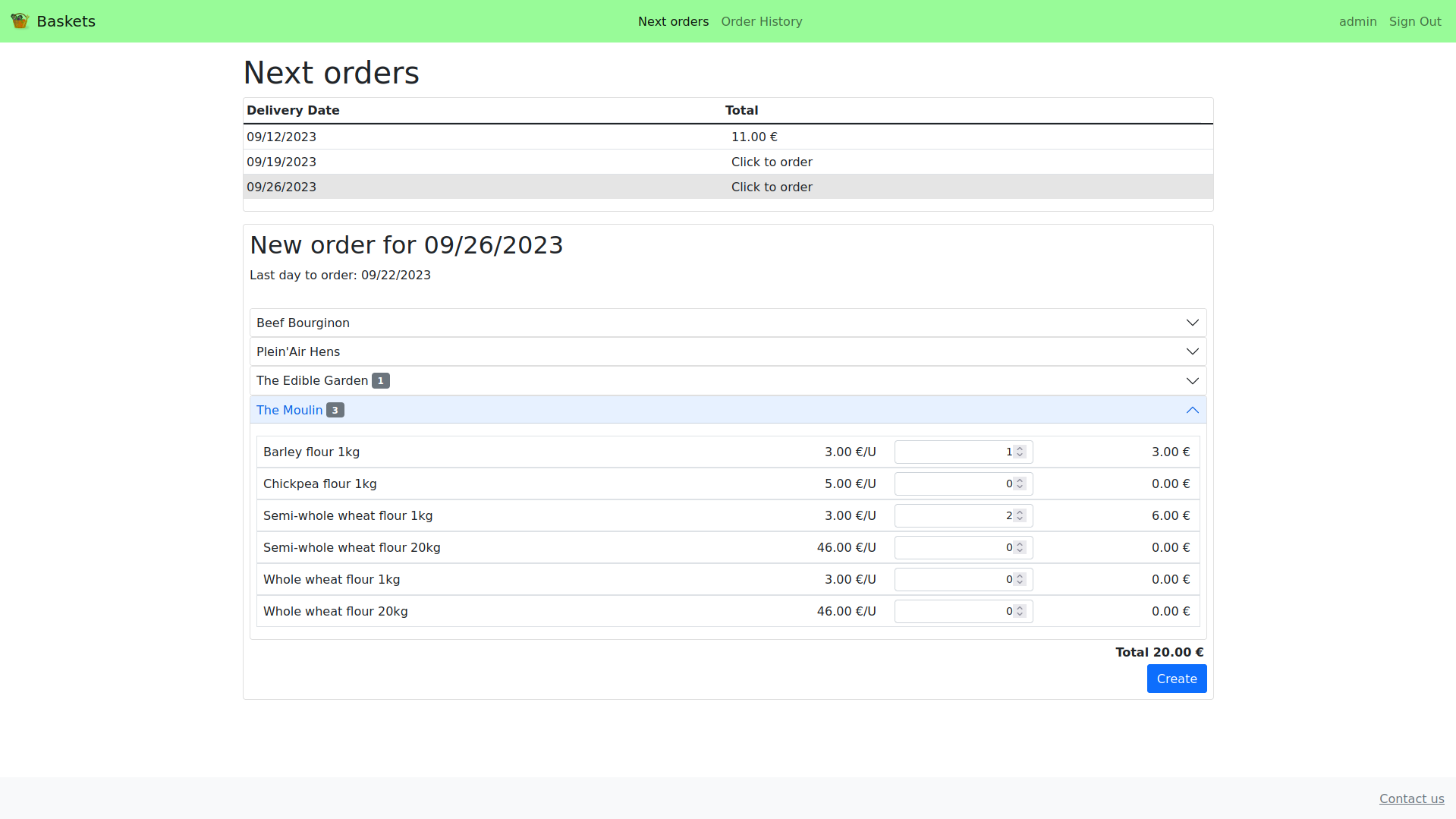
- Next Orders page:
- Shows the list of deliveries for which we can still order, in chronological order.
- Clicking on each delivery opens a frame below showing delivery details: delivery date, last day to order and available products arranged by producer.
- User can create one order per delivery.
- Orders can be updated or deleted until their deadline.
- Order history page:
- Shows a list of user’s closed orders in reverse chronological order.
- Clicking on each order will open its details below.
- Password reset:
- In “Login” page, a link allows users to request password reset entering their email address.
- If an account exists for that email address, an email is sent with a link to a page allowing to set a new password.
- Profile page:
- Clicking on username loads a page where users can view and update its profile information.
- Contact us page:
- A link on footer loads a page with a contact form. The message will be sent to all staff members.
All functionalities except “contact” requires authentication.
Users with both “staff” and “superuser” status can access admin interface.
- Users page:
- Manage each user account: activate/deactivate, set user groups and set
staff status.
- Groups page:
- Manage groups.
- Email all group users via a link.
- Producers page:
- Manage producers and its products (name and unit price).
- Deactivate whole producer or single product:
- Deactivated products won’t be available for deliveries.
- If a product with related opened order items is deactivated, those items will be removed and a message will be shown to email affected users.
- Export .xlsx file containing recap of monthly quantities ordered for each product (one sheet per producer).
- If a product has related opened order items and its unit price changes, related opened orders will be updated and a message will be shown to email affected users.
- Deliveries page:
- Create/update deliveries, setting its date, order deadline, available products and optional message.
- If “order deadline” is left blank, it will be set to
ORDER_DEADLINE_DAYS_BEFORE before delivery date.
- View total ordered quantity for each product to notify producers. A link allows seeing all related Order Items.
- If a product is removed from an opened delivery, related opened orders will be updated and a message will be shown to email affected users.
- In “Deliveries list” page:
- View “number of orders” for each delivery, which links to related orders.
- Export order forms:
- Once a delivery deadline is passed, a link will be shown to download delivery order forms in xlsx format.
- The file will contain one sheet per order including user information and order details.
- Action to email users having ordered for selected deliveries.
- Orders page:
- View user orders and, if necessary, create and update them.
- In “Orders list” page:
- Export .xlsx file containing recap of monthly order amounts per user.
- If one or several orders are deleted, a message will be shown to email affected users.
- Mobile-responsiveness: This has been achieved using Bootstrap framework for user interface. Moreover, Django admin interface is also mobile responsive.
- API: User orders can be managed using an API. See API reference for further details.
- UI Translation: Translation strings have been used for all UI text to facilitate translation. See UI Language for further details.
In addition to Django, the following libraries have been used:
Required versions can be seen in requirements (pip) or Pipfile (pipenv).
$ git clone https://github.com/daniel-ob/baskets.git
$ cd baskets
Then run:
And finally, create a superuser (for admin interface):
$ docker compose exec web python manage.py createsuperuser
Please note that, for simplicity, console email backend is used by default for email sending, so emails will be written to stdout.
docker exec baskets-web sh -c "python manage.py shell < populate_dummy_db.py"
- Change backend on
config/settings.py:
EMAIL_BACKEND = "django.core.mail.backends.smtp.EmailBackend"
- Set SMTP server config on
.envs/.local/.web:
# SMTP server config (if used)
EMAIL_HOST=
EMAIL_HOST_PASSWORD=
EMAIL_HOST_USER=
EMAIL_PORT=
EMAIL_USE_TLS=
Be sure you have ChromeDriver installed to run Selenium tests.
First launch db container:
$ docker compose up -d db
Then open virtual environment and install all dependencies:
$ pipenv shell
(baskets)$ pipenv install --dev
Finally, run all tests:
(baskets)$ python manage.py test
To run only functional tests:
(baskets)$ python manage.py test baskets.tests.test_functional
A Postman collection to test the API can be found here.
If settings.DEBUG is set to True, browsable API provided by REST framework can be visited on http://127.0.0.1:8000/api/v1/
All API endpoints requires token authentication.
JWT token pair can be requested on /api/token/ providing username and password (request Body form-data).
This returns access and refresh tokens.
To authenticate requests, access token must be added to headers:
Authorization: Bearer {{access_token}}
When expired, access token can be refreshed on /api/token/refresh/ providing refresh token.
List deliveries for which we can still order.
Response
[
{
"url": "http://127.0.0.1:8000/api/v1/deliveries/3/",
"date": "2023-06-27",
"order_deadline": "2023-06-23"
},
{
"url": "http://127.0.0.1:8000/api/v1/deliveries/2/",
"date": "2023-07-04",
"order_deadline": "2023-06-30"
}
GET /api/v1/deliveries/{delivery_id}/
Response
{
"id": 2,
"date": "2023-05-30",
"order_deadline": "2023-05-25",
"products_by_producer": [
{
"name": "producer1",
"products": [
{
"id": 1,
"name": "Eggs (6 units)",
"unit_price": "2.00"
},
]
},
{
"name": "producer2",
"products": [
{
"id": 2,
"name": "Big vegetables basket",
"unit_price": "1.15"
}
]
}
],
"message": "This week meat producer is on vacation",
}
Response
[
{
"url": "http://127.0.0.1:8000/api/v1/orders/30/",
"delivery": {
"url": "http://127.0.0.1:8000/api/v1/deliveries/2/",
"date": "2023-07-04",
"order_deadline": "2023-06-30"
},
"amount": "220.00",
"is_open": true
}
]
GET /api/v1/orders/{order_id}/
Response
{
"url": "http://127.0.0.1:8000/api/v1/orders/30/",
"delivery": 2,
"items": [
{
"product": 5,
"product_name": "Package of meat (5kg)",
"product_unit_price": "110.00",
"quantity": 2,
"amount": "220.00"
}
],
"amount": "220.00",
"message": "",
"is_open": true
}
{
"delivery": 3,
"items": [
{
"product": 14,
"quantity": 2
}
],
"message": "is it possible to come and pick it up the next day?"
}
Request must follow this rules:
- delivery
order_deadline must not be passed
- a user can only post an order per delivery
- all item products must be available in
delivery.products
Response
Orders can be updated until delivery.order_deadline.
PUT /api/v1/orders/{order_id}/
{
"delivery": 3,
"items": [
{
"product": 14,
"quantity": 1
}
]
}
Response
DELETE /api/v1/orders/{order_id}/
Response
Translation strings has been used for all text of user and admin interfaces,
so all of them can be extracted into messages files (.po) to facilitate translation.
In addition to default language (English), French translation is available and can be set on settings.py:
The server must be restarted to apply changes.
From base directory, run:
django-admin makemessages -l LANG
django-admin makemessages -d djangojs -l LANG
Where LANG can be, for example: es, es_AR, de …
This will generate django.po and djangojs.mo translation files inside locale/LANG/LC_MESSAGES folder.
Once all msgstr in .po files are translated, run:
django-admin compilemessages
This will generate corresponding .mo files.